One Platform. Four Layers.Zero Clusters.
Moorcheh is a four-layer serverless architecture that replaces your entire AI retrieval stack — vector database clusters, reranking APIs, observability middleware, and the engineering overhead to maintain them. Every layer deploys into your VPC as coordinated cloud-native services. Every layer scales independently. Every layer costs $0 when idle.
Agentic Memory · SDKs · MCP
Retrieval · Generation · State
MIB Compression · ITS Scoring
Sovereign Cloud · SaaS
What Disappears When You Switch to Moorcheh
Traditional AI search requires five separate systems running 24/7. Moorcheh replaces all of them with serverless microservices that scale to zero.
Vector Database Cluster
~$591,000/yrQdrant / Pinecone / Weaviate running on memory-optimized instances (r7g.2xlarge) + Kubernetes orchestration.
Serverless Binary Search
~$18,000/yrInformation-theoretic compression + Hamming distance search on AWS Lambda. No cluster. No instances. No Kubernetes.
Reranking API
~$1,500,000/yrCohere Rerank or similar. External API call on every query to compensate for approximate search.
Built-in Re-ranker
$0Native re-ranking pipeline. No external API calls. No per-query fees. No data leaving your VPC.
Middleware & Observability
~$378,000/yrLangSmith + LangChain tracing layer. Token overhead. Separate subscription.
Built-in Tracing & Monitoring
$0Full observability in Mission Control. Log and trace every retrieval path. No middleware subscription.
Engineering Team
~$450,000/yr2 DevOps + 1 Backend engineer dedicated to cluster maintenance, scaling, and pipeline ops.
Fully Managed
$0SLA-backed managed service. No cluster provisioning. No capacity planning. No 3 AM pages.
Total Annual Cost
$2,500,000+/yrRunning 24/7 regardless of usage
Total Annual Cost
~$36,000/yr + license$0 when idle
98% cost reduction across the full retrieval stack.
From five systems to one. From $2.5M to $36K.
Why It's Faster, Cheaper, and More Accurate
Three architectural decisions that make the 90% cost reduction possible.
Instant Searchability
Documents are searchable the instant they land. No indexing queues. No rebuild windows. No stale results while your pipeline catches up.
Traditional vector databases require index rebuilds that can take minutes to hours as your dataset grows. Moorcheh's architecture eliminates the indexing step entirely — every document is available for retrieval the moment it's ingested.
Deterministic Retrieval
Stop getting the wrong document at the worst moment.
Every vector database built on HNSW gives you approximate results — probabilistic nearest neighbors that are fast but not guaranteed to be correct. For legal discovery, financial compliance, and medical records, “probably the right document” is a liability.
Moorcheh's information-theoretic scoring delivers 100% deterministic recall. The exact nearest neighbors. Every time. Not approximate. Not probabilistic. Mathematically guaranteed.
| Attribute | Moorcheh | Traditional VDBs |
|---|---|---|
| Architecture | Deterministic | Approximate (ANN) |
| Algorithm | Exact Bitwise Scan | HNSW Probabilistic Graph |
| Recall | 100% | 95–99% (varies) |
| Compliance | Audit-safe | Probabilistic gap |
| Avg Latency | 9.6ms | 37–87ms |
32× Compression — The Serverless Unlock
This is the architectural breakthrough that makes everything else possible.
Moorcheh's information-theoretic binarization compresses float32 embeddings by 32×. A 4KB vector becomes a 128-byte binary code. At this size, vectors load from DynamoDB or S3 into a Lambda function in single-digit milliseconds — searched using Hamming distance, a bitwise CPU operation orders of magnitude faster than cosine similarity.
This is what eliminates always-on RAM clusters. When your vectors are tiny and your search is a native CPU operation, the monolithic database vanishes — replaced by serverless microservices that spin up on demand and scale down to zero.
Ingest Anything. At Any Scale.
From a single PDF to millions of multimodal documents — drop the file, it's searchable.
Multimodal File Ingestion
PDFs. Images. Spreadsheets. Scanned documents with OCR. Word files. Videos. MP4. Up to 5 GB per file via pre-signed S3 upload.
Every file is processed asynchronously — chunked, embedded, and made searchable without blocking your application. Attach metadata at upload time for filtered retrieval later.
No format conversion. No preprocessing pipeline to build. Drop the file. It's searchable.
Built for 10M+ Documents
Moorcheh's namespace-scoped architecture isolates data at the tenant level — each namespace operates independently with its own documents, metadata filters, and access controls.
Ingestion runs in parallel across async workers. Search runs across compressed binary indexes. Both scale horizontally without provisioning decisions.
10M+ documents per deployment. Metadata-filterable at query time. Namespace-level lifecycle management for multi-tenant SaaS.
Your Cloud. Your Rules. 10 Minutes.
Sovereign Cloud in your VPC or managed SaaS — same API, your choice.
Sovereign VPC Deployment
Deploy Moorcheh's full stack into your own AWS, GCP, or Azure VPC in under 10 minutes. CDK, Terraform, or ARM templates — your choice.
428 coordinated cloud-native assets deploy automatically — all configured, connected, and production-ready:
No clusters. No Kubernetes. No always-on instances. Everything runs as serverless microservices under your cloud account, your billing, your security perimeter.
Your data never leaves your environment. Full PIPEDA, GDPR, SOC 2, and HIPAA compliance by architecture — not by policy.
Managed SaaS
Go from zero to production in minutes. Same API, same performance, same SDKs. No cloud account required.
Start building on SaaS. When compliance requirements demand sovereign deployment, migrate to your VPC with zero code changes — same endpoints, same data model, same behavior.
Search and Reason. One API.
Two endpoints. Retrieval and generation. Everything else is handled internally.
/search — Precision Retrieval
/search endpoint
Hybrid search in a single syntax. Combine semantic similarity with metadata filters and keyword constraints in one query.
Use #keyword to enforce exact term matching alongside vector search. Filter by any metadata field attached at ingestion. Retrieve raw payloads, scores, and trace data in one pass.
No separate keyword index. No query federation. One endpoint.
Unique to Moorcheh: #keyword constraints give you exact-match precision inside semantic search — the hybrid search that compliance teams actually need.
/answer — RAG in One Call
/answer endpoint
One API call. Full RAG pipeline. Moorcheh handles embedding, retrieval, context injection, and prompt construction internally. You choose the model.
Bring any LLM: Claude 4.5, Llama 4, DeepSeek R1, or your own fine-tuned model. Moorcheh retrieves the relevant context and injects it — you're not locked into any provider.
Build, Monitor, Ship
Everything you need to build, observe, and ship AI applications.
Mission Control
console.moorcheh.ai
Full observability at console.moorcheh.ai. Monitor latency per endpoint. Trace every retrieval path — which documents were returned, with what scores, through what filters. Prototype and test agents before deploying to production.
Built-in tracing and monitoring means no LangSmith subscription, no LangChain middleware overhead, no separate observability stack. The same dashboard that runs your search also audits it.
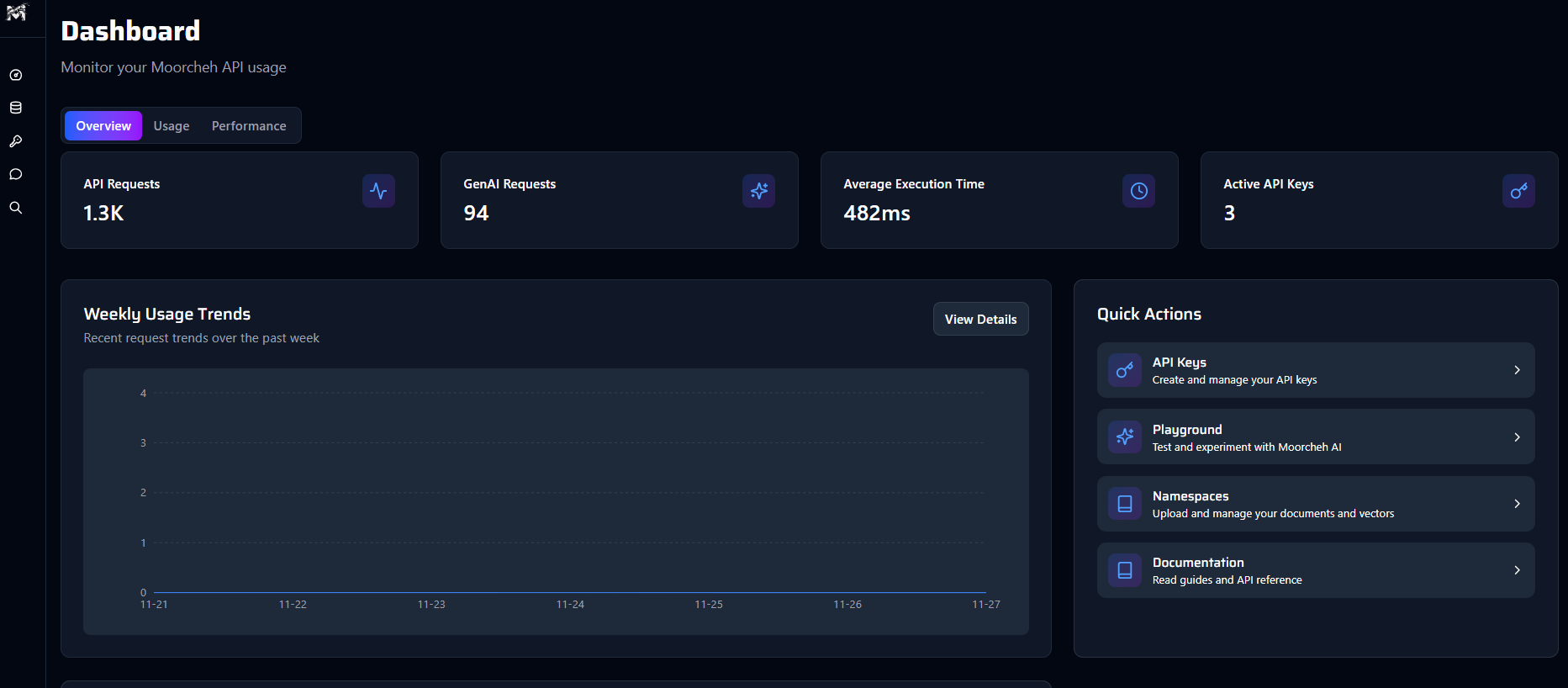
Replaces: LangSmith + LangChain observability layer (~$378,000/yr saved)
Open ConsolePython & Node.js SDKs
Native SDKs
Fully typed. Async-first. Install from PyPI or npm and start querying in minutes. Every endpoint, every parameter, every response — typed and documented.


Export to Code
Next.js Boilerplate
Design in the Console, export config to our Next.js Boilerplate. Deploy anywhere.


The Cerebellum for Autonomous Agents
Stop building stateless bots that forget everything between sessions.
Your AI agent reviews a 200-page contract on Monday. On Thursday, a user asks about clause 14.2. Without persistent memory, the agent re-processes the entire document from scratch. With Moorcheh's memory layer, it recalls the full context instantly — what it read, what it concluded, what actions it took.
Moorcheh provides the persistent, stateful memory layer that autonomous agents need to remember, reason, and evolve over time.
Memory is not just storage. It is State.
Short-Term Working Memory
Active context for the current task — what the agent is working on right now, the documents it's retrieved, the reasoning chain in progress.
Long-Term Procedural Recall
Persistent knowledge across sessions — past decisions, learned preferences, accumulated expertise. Available instantly on the next interaction.
Plug into what you're already building.
Official connectors for the industry's leading frameworks

Model Context Protocol
The universal standard. Connect Claude Desktop and compatible IDEs directly to your Moorcheh memory brain without custom code.

n8n
Orchestrate multi-step agentic workflows visually. Drag-and-drop Moorcheh nodes to build complex AI pipelines.

LangChain
Official Retriever & VectorStore implementation. Drop us seamlessly into your Python or JS chains.
LlamaIndex
Native VectorStore integration. Build advanced RAG engines and query pipelines with full metadata support.
Built for Engineers. Trusted by Teams.

.png)
Moorcheh cut our retrieval infrastructure cost by over 90%. We went from managing a Qdrant cluster to a single API call.
Engineering Lead
ShyftLabs
The deterministic retrieval was the deciding factor for us. In healthcare, approximate search isn't an option.
CTO
drPal.ai
We deployed a full RAG stack into our VPC in under 10 minutes. Our previous setup took three engineers two months.
Head of AI
Evalia.ai
Technical Deep Dive
The questions serious engineers ask before committing to infrastructure
Core Technology & Accuracy
The Paradigm Shift
Start ArchitectingBuild the next generation of agentic AI with Moorcheh's unified semantic infrastructure.
One API. Full control. Deploy anywhere.